Process Injection on Linux - Prevention and Detection
This article is part 3 of a 5 parts series on process injection on Linux.
In the first two (2) parts of this series, I went through defining process injection and presenting various facilities and techniques supporting them. It is now time to look at how to prevent and detect them. I'm assuming the reader is familiar with process injection and read the first two (2) parts of this series. I'm also assuming that the reader has solid Linux system administration knowledge and skills.
During this research, I would have really liked to check how various EDRs perform against various injection techniques, but found that vendors make it way too costly, finance- and effort-wise, for researchers (and potential clients!) to get a trial version. I abandoned the idea, but I think it would have been nice to check products and collaborate with vendors if any blindspots had been found (yep, not my loss here), and present a table of EDRs and their current state. However, given these posts, hopefully, defenders will be able to perform their own checks to assess the coverage of their chosen security solutions.
Preventing Injection
Inheriting from its UNIX roots, the reader might be aware that Linux, in its default configuration, isn't the system with the most bells and whistles to lock down a system. Nonetheless, there is a variety of parameters, facilities and modules that can be used by developers and system administrators to prevent injection. This section presents the privileges required to perform an injection, followed by a tour of developer-oriented prevention facilities and, finally, administrator-oriented facilities.
Injection conditions
In a default configuration, a user can ptrace any process with
an effective user id (euid) equal to its uid and their uid. In other
words, it cannot ptrace setuid binaries (when the executable's
owner is not the user itself) or processes of an other user. In
practice, this makes it impossible to elevate privileges by observing
or modifying another user's process. In the same spirit, memory writes
using /proc/<pid>/mem or process_vm_writev is not possible when
tracing is not allowed. However, processes that have the CAP_SYS_PTRACE
capability have the right to trace any process1; remember
that uid 0 (root) has all capabilities and that capabilities are
associated with files/executables rather than users.
if (tracer-caps & CAP_SYS_PTRACE)
allowed
else if ((tracer-uid == tracee-euid) && (tracer-uid == tracee-uid) && (tracer-saved-setuid == tracee-uid)
allowed
else
disallowed
prctl/PR_SET_DUMPABLE
prctl is a system call that manipulates various aspects of the behavior of the calling thread or process. One of the many aspects that can be changed is the "dumpable" attribute of a process. This attribute determines whether core dumps are produced when the process receives a signal whose default behavior is to produce a core dump. Preventing core dumps can be useful when a process stores sensitive data (passwords, decryption keys, etc.) in memory and that they shouldn't be copied to disk to prevent them from being exposed.
prctl(PR_SET_DUMPABLE, 0);
Not quite so intuitively, this attribute also controls whether the
calling process can be attached to using ptrace when the tracer does
not have the CAP_SYS_PTRACE capability in the user namespace of the
target process. In other words, if the process/user doesn't have the
CAP_SYS_PTRACE capability, it cannot trace processes that cleared
this attribute. In practice, it restricts tracing to privileged
processes.
A simple way to query this attribute on a process is to try to attach
to it using the strace utility.
Most developers do not bother about threat models that assume the user account has been breached. I won't go into the underlying debate, here, but merely point out how this can reduce the damage of a compromise. Well-known softwares that make use of this attribute are OpenSSH, tor and KeePassXC, among others.
Secure Computing (seccomp)
seccomp is a BPF-based filter that can be used to disable syscalls.
It was originally designed to safely run untrusted code, but can equally
be used to limit the impact of an exploited vulnerability. For example,
it can disable all syscalls but open, close, read, write and
exit. The idea being that, once a process is about to enter its
"working" state, it disables the syscalls that should not, under
expected conditions, be used. Afterwards, whenever a disabled syscall is
invoked, the kernel refuses to proceed and returns, terminating the
process or the thread.
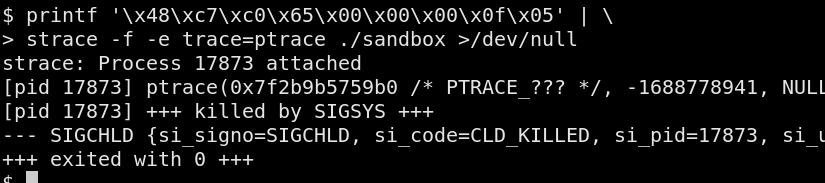
Here's a small list of well-known softwares that use or support
seccomp: OpenSSH, QEMU (when used with the --sandbox option), tor,
Chrome and Firefox.
The BINDNOW and RELRO linking flags
In part 2, I presented an injection technique that leveraged a
process's GOT to hook and maintain execution. This technique relies
on the lazy symbol resolution of runtime dependencies of programs.
Without these flags, whenever a program uses the C library's printf
function, for example, on startup, the dynamic loader only loads the
C library (libc.so) in memory. The actual location of printf is only
resolved when the program tries to use it for the first time; subsequent
calls the address that was found. This laziness makes startup times
smaller since no symbols (and there can be many) needs to be resolved.
As we can see, the end result is that an attacker can redirect execution
by modifying the GOT.
To prevent GOT modifications, the BINDNOW feature instructs the dynamic
loader to resolve all symbols at load-time. The RELRO feature, on the
other end, makes the GOT as read-only. These features are generally used
together, but nothing prevents a developer to use one or the other. When
only the RELRO feature is used, the ELF's internal data sections
(.init_array, .fini_array, .got, etc.) of a program are positioned
before the program's data sections (.data and .bss). Strictly
speaking, in that context, RELRO is a misnomer.
# compiling a C program "full relro"
gcc -Wl,-z,relro -Wl,-z,now -o main main.c
Note that, technically, these features do not prevent process injections.
Rather, they mitigate vulnerabilities that rely on write primitives
that target the GOT. Since there are well-known bypasses to this
mitigation, they should be seen as part of the organization's
defense-in-depth strategy. An attacker capable of executing arbitrary
code on a system can still abuse the "punch through" behavior of
ptrace and /proc/<pid>/mem, or use mprotect to work around
non-writable memory sections.
Yama/ptrace_scope
Yama is a Linux Security Module that collects system-wide DAC security protections that are not handled by the core kernel itself.
As mentioned in Yama's documentation, PR_SET_DUMPABLE is not
sufficient to prevent process injection (and other forms of abuse)
entirely. In effect, any process that has the CAP_SYS_PTRACE
capability can use ptrace on any process running on the system;
in practice, generally, only root.
To provide more granular control about what processes may use ptrace
on another process, Yama provides the ptrace_scope kernel
configuration parameter and adds an option to prctl. ptrace_scope
enables, for example, to only allow ptrace-ing a process (the tracee)
when it is part of a parent-children relationship with the tracer, or those
that have been explicitly declared using a prctl PR_SET_PTRACER call.
It also enables limiting ptrace-ing to only processes that have the
CAP_SYS_PTRACE capability; effectively setting PR_SET_DUMPABLE to
0 to all processes on the system. And, finally, disabling ptrace-ing
entirely; without the ability to re-enable ptrace-ing. Depending on
the Linux distribution, the default
value of ptrace_scope either does not enforce any protection or only
in the context of process hierarchies.
An environment with high security requirements may be intereted in
disabling ptrace altogether.
# apply on the live system
sysctl -w3 kernel.yama.ptrace_scope
# preserve configuration across reboots
printf '\nkernel.yama.ptrace_scope=3\n' | sudo tee -a /etc/sysctl.conf
Yama also protects processes against /proc/<pid>/mem- and
process_vm_writev-based injection techniques by disabling the
"punch trough" mechanism.
SELinux
In part 2, I demonstrated an injection technique that
uses mmap to allocate a new memory page and mprotect to setup its
protection flags according to the W^X policy. One thing that I have
often seen in publications (on binary exploitations and process
injection) is the use of the rwx protection flags passed to mmap.
While this work in most configurations because Linux does not
enforce the W^X policy, it only starts with safe defaults, it's
stealthier to have a legitimate-looking access mask. However,
the SELinux security module allows system administrators to enforce
the W^X policy and make many injection techniques unusable.
SELinux is a complex beast and, here, I'll focus on a few global boolean flags that can be used by administrators to apply restrictions on all processes. Simply note that process- or user-specific restrictions can also be applied by using policies.
execmem
This boolean flag enforces the W^X policy by preventing anonymous (non-file backed) memory mappings and writable private mappings to be made executable.
// https://github.com/SELinuxProject/selinux-kernel/blob/6b9921976f0861e04828b3aff66696c1f3fd900d/security/selinux/hooks.c#L2421
#ifndef CONFIG_PPC32
if ((prot & PROT_EXEC) && (!file || (!shared && (prot & PROT_WRITE)))) {
/*
* We are making executable an anonymous mapping or a
* private file mapping that will also be writable.
* This has an additional check.
*/
int rc = task_has_perm(current, current, PROCESS__EXECMEM);
if (rc)
return rc;
}
#endif
This flag, and all other boolean flags, can be controlled using the following commands.
# list boolean flags
semanage boolean -l
# get the value of a specific flag
getsebool deny_execmem
# set the value of a flag
setsebool -P deny_execmem 1
execheap
This boolean flag enforces whether a process's heap can be marked
executable. It is a variant of execmem whereas it only applies to
heap memory.
execstack
This boolean flag enforces whether a process's or thread's stack
can be marked executable. It is a variant of execmem whereas it
only applies to the stack.
deny_ptrace
When set, the deny_ptrace boolean disables the ptrace system call
entirely. It has the potential to, effectively, make any ptrace-based
injection technique unusable. It is the equivalent of setting
Yama's ptrace_scope parameter to something between 2 and 3; where
the system call is disabled even for users with the CAP_SYS_PTRACE
capability, but the ability the re-enable the system call, if necessary.
AppArmor
AppArmor is an other security module for Linux that constrains how a program (its processes) may interact with the system. It can control, for example, what files a process may read or write, what capabilities it can acquire, and integrates with various facilities such as mount points, signals, DBus, etc.
It is designed around the context of profiles, applied to processes,
based on declarative permissions. If a permission isn't granted by
an AppArmor profile, the operation is denied by the kernel. For example,
the below profile for redshift specifies enables it to communicate
with the X11 server or Wayland, using DBus and open files matching a
particular pattern.
# /etc/apparmor.d/usr.bin.redshift
/usr/bin/redshift {
#include <abstractions/base>
#include <abstractions/nameservice>
#include <abstractions/dbus-strict>
#include <abstractions/wayland>
#include <abstractions/X>
dbus send
bus=system
path=/org/freedesktop/GeoClue2/Client/[0-9]*,
dbus receive
bus=system
path=/org/freedesktop/GeoClue2/Manager,
# Allow but log any other dbus activity
audit dbus bus=system,
owner @{HOME}/.config/redshift.conf r,
owner /run/user/*/redshift-shared-* rw,
# Site-specific additions and overrides. See local/README for details.
#include <local/usr.bin.redshift>
}
Distributions provide a relatively small set of AppArmor profiles, but there is usually profiles for common network-exposed services; BIND9, MariaDB, tor or Squid. Profiles for softwares with high configurability potential, such as Apache, are best designed by system administrators.
Detecting Injection
Although it's much less efforts to have good preventative measures in place, some things might get through. In this section, I'll present facilities and techniques to detect when a technique is used or after they've been used (i.e. when it's too late). To this end, let's suppose that there are no preventative measures in place and that an attacker is targeting a system.
auditd
auditd is Linux's audit subsystem's events collection engine. It generates event messages for rules specified by the administrator. It can, for example, generate messages for any invocation of a syscall with particular arguments, and tag events for triaging. It can also watch filesystem files or hierarchies for various types of accesses or modifications. Generated messages can be logged locally and/or forwarded to a central logging server.
While it does its job somewhat well, auditd, is severely limited on
some aspects. For instance, it does not support any kind of subpath-based
filesystem events filtering. In other words, accesses to the .ssh
directory of users' home directories cannot be monitored with something
along the lines of /home/*/.ssh/. Instead, one has to specify a
filesystem watchpoint at /home/ and then filter the events using
another tool. While this behavior works, it is exceptionally noisy in
busy environments.
For example, this makes it particularly noisy to monitor for
injection techniques leveraging /proc/<pid>/mem as every writes under
/proc/
need to be logged. As such, its much better to forward the logs to a
logging server with filtering capabilities that will, in turn, trigger
alerts on interesting events.
Similarly, auditd misses some events when they're namespaced;
i.e. in containers. This limitation makes it impossible, for example,
to detect some injection techniques being used when processes run in a
container.
In the same spirit, the subsystem, on some filesystem operations,
generate events that only contain a filename (not the full path. This
makes it pretty difficult for analysts to assess quickly whether
something should be further investigated.
In any case, like any ruleset, if the auditd rules aren't
exhaustive, some attacks will fly through undetected (it could be
argued that some incidents will pass through anyways, but). Make sure
you stay up to date with the latest adversary techniques and have
various telemetry collection systems to avoid creating blind spots.
A process injection detection ruleset for auditd is available at
https://github.com/antifob/linux-prinj/blob/main/auditd.rules
Detecting tracees
While auditd provides detailed coverage over a system, sometimes, it's
necessary to perform a manual inspection. Whenever a process is attached
to by another process, the kernel marks it in the /proc/<pid>/status
file under the TracerPid entry.

# list all tracers
grep ^TracerPid: /proc/*/status
# list what processes trace what
awk '/^TracerPid:/{if($2!="0"){split(FILENAME,f,"/");print $2" -> "f[3];}}' /proc/*/status
This technique isn't suitable for real-time monitoring, however, and
usage of a system such as auditd or an eBPF-based monitor is strongly
recommended.
Memory mappings
The /proc/<pid>/maps file provides information on the virtual address
space of a process. It indicates, for each memory segment:
- their beginning and end addresses;
- their protections (
read,write, executable andprivate orshared); - their offset (matches the executable's
LOADsections' offset); - the major and minor device number of the backing file (when file-backed);
- the inode of the backing file (when file-backed);
- the path of the backing file.
It's important to note that file-backed memory segments have a 1:1 mapping with a file region (possibly the whole file). As such, the memory region should be identical to the data on disk. Dynamically-allocated memory used for computation, on the other end, is not file-backed, or anonymous.
When inspecting a process, one can check that the file-backed memory region matches its representation on disk to evaluate whether it was altered. For example, writing a payload to a code cave, or overwriting instructions, is noticeable when comparing memory and file.
Signals disposition
As I indicated in part 2 of this series, a malware can, as a persistence mechanism, hook itself into a process's execution path by way of the signals facility. It can either make use of an unused signal number to register its own handling routine, or hook an existing handler.
For defenders, the question is: how can one check that a process's signal handlers are legitimate?
To inspect a process's signal disposition, the /proc/[pid]/status
file can be inspected. The SigCgt field is a bitwise mask of "caught
signals" (signals for which there is a handler). The other fields
indicate the queued/pending signals, signals that are blocked
(queued but not delivered) and ignored (never queued for delivery).
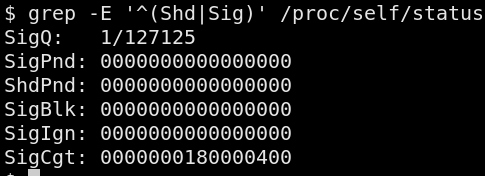
While we have some information available about a process's signal
handlers, it is impossible to assert, without knowledge of the program's
internals, that the handlers are legitimate, nor is there
a facility to collect the address of these handlers. Ironically, one can
use process injection to dump a process's signal handlers, or use ptrace
to track how a process behaves with particular signal inputs.
Note that, usually, handlers are file-backed. If a handler is positioned in an anonymous memory segment, it, effectively, means that the handler's code was dynamically generated. While it is not impossible, it is rare enough to be a serious indicator of something potentially malicious.
Timers
The /proc/<pid>/timers file provides information about the POSIX
timers that were created by a process. For each timer, it provides
4 fields: the timer identifier, the signal number used for delivery
(only valid when using signal delivery), the notification attributes
and the clock source identifier. For example, the below listing is
associated with the program at
https://github.com/antifob/linux-prinj/blob/main/misc/proc-timers
It shows two (2) signals; using thread notification and signal
delivery, respectively. Note that timers using setitimer are
not listed in the timers file.
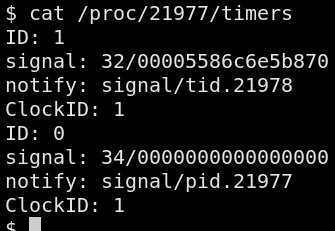
Analyzing a process's timers require intimate knowledge of how a
program works. Many softwares don't use timers, but many others do.
Assuming that the program does make use of timers, one can see that
the thread-backed timer, above, has the handling code's address stored
in the signal: field. This information can be used to verify that
the code resides in a file-backed memory segment and that it has not
been tampered with by comparing memory with the data on disk.
Since the setitimer timers are not listed in this file, one has to
rely on regular signal disposition analysis (documented above) for
the SIGALRM, SIGVTALRM and SIGPROF signals.
Threads
The /proc/<pid>/task/ directory provides a list of thread/task of a
process. Each process has at least one (1) thread (the main thread) and
each threads created will have an entry in that directory. And since
threads have a set of private data, one can find it in the thread's
directory. For example, each thread has its own stack and this is
reflected in /proc/pid/task/tid/maps.
When one knows how a program is implemented, it is possible to evaluate
whether it is possible for a process to have threads and respond
accordingly. For example, the cat binary is single-threaded. If one
finds an instance of cat that has multiple threads, it is highly
suspicious.
Child processes
The /proc/<pid>/task/<pid>/children file provides the list of children
a process has. Since the line between threads and children is blurried,
it has the same indicators as threads; mentioned above.
What we've seen so far
In this article, I covered different ways to prevent and detect
various injection techniques. As with everything, there's no silver
bullet. However, a few simple steps can be taken to improve the
security of systems. The simplest "quick win" one could take away for
the vast majority of environments will be a strong (2 or 3) Yama
ptrace_scope policy. Additionally, activating SELinux will make
attackers' life much more difficult in general and using it in
enforcement mode is strongly encouraged; even if it's just
to deny execmem, execstack and execheap. In any case, defenders
should assume that, to some degree, these preventative measures will
fail and that efficient telemetry systems are installed.
Articles in this series
- Part 1 - Introduction
- Part 2 - Injecting into Processes
- Part 3 - Prevention and Detection
- Part 4 - Advanced Injection Topics
- Part 5 - Technical Reference
References
- auditd(8)
- audit.rules(7)
- CentOS - SELinux Boolean List
- Linux - Yama LSM Documentation
- OpenSSH - platform-tracing.c
- prctl(2)
- proc(5)
- ptrace(2)
- seccomp(2)
Unless
ptrace_scopeis set to3. ↩︎