Process Injection on Linux - Introduction
About a year ago, my security news feed contained a few posts about process injection. While I was vaguely aware of the technique and understood the idea, I had never looked into the details and, as such, couldn't quite get what was the big deal about it. I mean: code execution is code execution, right? If one's able to get code execution, does it really matter if they move into another process? Is it really that powerful or is it just fancy-looking? So, after reading the articles, I only wanted to experiment with it to see for myself what all the fuss was about. All those posts, however, were about injection techniques in Windows environments and, while I do do some security work with Windows, I am much, much more comfortable in Linux-based environments. Looking for equivalent articles targeting Linux kind of let me hanging dry.
A couple of weeks later, I sat down one night and started the research clean. After a couple of days of the classic "experiment, analyze" cycle, I had developed a nice little toolset of proof of concepts programs and, more importantly, acquired knowledge about the technique. Process injection is, in my opinion, one of the most simple, elegant and, yet, quite powerful technique that exists. The more I dug in, the more I started to think about its implications and, more importantly, how to best protect oneself against it.
To that end, I thought about posting this series of articles designed to, hopefully, put everyone on the same foot: help defenders prevent and detect the technique, and testers use it to test their clients. For this, I try to take a simple step-by-step approach that should help less technical people follow along.
What is process injection anyway?
Process injection is a post-exploitation technique with evasion as its primary objective. It is performed by injecting malicious code into a host process's address space and executing it. The idea being that, since it hides inside a legitimate process, there is less risk that it is going to be detected. Once injected, the malicious code is, from an operating system's perspective, part of its host and can perform any action that it can perform; read/write memory, execute code and (ab)use its privileges.
Note that this technique differs from more common execution hijacks such
all those PATH-related (LD_LIBRARY_PATH, LD_PRELOAD, etc.)
techniques in that the injection is performed after the process's
address space has been completely setup; PATH-related techniques take
place during the process's initialization phase.
Process injection is most commonly done for legitimate purposes such as debugging, instrumentation and defense, but can also be done for more illegitimate purposes such as defense evasion, backdooring and information stealing. On MITRE's ATT&CK framework, these two (2) technique categories are identified as T1055 and T1574, respectively.
Operating systems 10112
Process injection sounds complicated. It's not, really, but it requires a solid understanding of operating systems. If you do have that knowledge, feel free to skip to the next section. In this one, I'll go over a few key concepts and terms that are necessary to understand this series. We'll go back in time and gradually build up to present the elements relevant to the topic. I'm assuming that the reader has a more-than-functional knowledge of information technologies or is technically-inclined, and knows basic assembly programming. I also recommend additional reading below; in case you're interested in a better and deeper coverage.
Programs and processes
I think it is safe to say that the concept of computing processes was introduced with the arrival of time-sharing operating systems. Before those, a machine would only execute a single program at a time (a job). With some improvements, downtimes caused by the necessity to switch jobs (at the time, written on punch cards) were reduced by jobs queuing machinery and the concept of batch processing (having multiple jobs queued). With this machinery, humans no longer became a bottleneck; jobs switching was largely automated. Still, whenever one wanted to run a program on the computer, they had wait for queued jobs to finish. And the more time-consuming those jobs were, the longer one had to wait to get their result. Furthermore, if any of those jobs failed because they were bugged, everyone wasted their time. Imagine having a 30 seconds computation come back 3 days later because that professor had that big computation queued up... and then theirs (or yours) fails at the end because a semi-colon was missing.

With everyone wanting faster (and fairer) usage of their shared computer, the technique of time-shared execution was adopted. Essentially, the machine would run each job for a small time period, saving the machine's state (the CPU registers) at the end of the period, and switch to another job by restoring its state and continuing its execution. Using this technique, over time, small jobs would be performed faster and buggier programs would crash sooner; everyone getting faster feedback and being more productive.
Even if punch cards were replaced with binaries and disks, time-sharing is still fundamental to today's computing. With powerful machines and small time slices, it provides the illusion that everything happens in parallel, but the operating system still keeps track of the state of every processes and switches between them at really small intervals. Each time a program gets started, a process is created and is tracked by the operating system until the program terminates.
A program is a set of instructions and a process is an instance of a program being executed by a machine. Additionally, due to time-sharing, processes run concurrently, not in parallel.
Virtual memory
If you picture a modern machine's memory, you'll realize that, every second, it's filled with the code (and data) of every processes that is being executed. However, if you look at the machine's memory from a process's perspective, nowhere will you find the data of other processes. The feature that supports this is called virtual memory. It is implemented by modern processors and used by operating systems to compartimentalize processes for stabilility, portability and security reasons. Without virtual memory, every program that's written to use a specific memory address range, say 0x400000 to 0x500000, would corrupt each others. Additionally, a malicious program could simply steal your password when you login by reading the login process's memory. And the situation would only be worse on multi-user systems...
To eliminate these issues, processors enable operating systems to associate a memory mapping table to each processes they manage. This mapping table is used to let the processor transparently remap an address used by a process to a different physical address. This way, two (2) or more processes can use the same address range, but, since they will mapped to different physical addresses, no corruption can occur.
In practice, a machine's physical memory is divided into segments, called pages (of 4096 bytes on the Intel architecture), and mapped to a process's address space, composed of virtual memory, by the operating system. In its simplest form, there is a 1-to-1 mapping between physical addresses and virtual addresses, but that needs not to be the case; and is generally not.

Since every pages of physical memory need not to be accessible by every processes, an operating system only maps the pages that are relevant to them. Then, when a process tries to access a memory area, the processor looks up the process's mapping table to check the physical address that matches the virtual address and uses that completely transparently. If a memory area isn't backed by a physical page, a memory access violation error occurs.
Operating systems present a fake view of physical memory to processes: virtual memory. Physical memory is divided into pages and mapped to arbitrary (page size-aligned) addresses of a process's virtual memory space. These usable memory ranges compose a process's address space.
Engineering and code reuse
So far, we've looked at some quite low-level details so let's go back to the surface a bit.
One of the oldest cost reduction technique of engineering is component reuse. In essence, one designs and builds a component to be reused in as many products possible. In software engineering, this technique naturally translates into writing programs to be reused by other programs. These reusable programs usually take the form of what's called libraries and can be used to solve common (e.g. strings manipulation) or very specialized (e.g. cryptography) problems. This action of putting different pieces of codes together to form a single program is called linking and is performed by a specialized program called a linker. As we'll see here, due to the flexible nature of software, there are different types of linking and linkers.

Static linking is the oldest type of linking and is performed at build time. A simple example is a program composed of multiple source files. All those files are compiled individually and their output linked together to form a single executable.
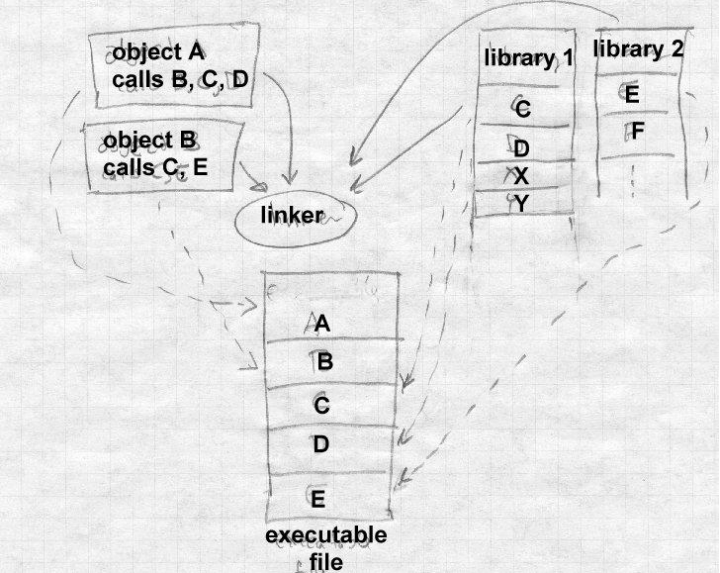
While this technique is elegantly simple, it has its drawbacks. Until relatively recently, storage space was a quite scarce resource and various tricks had to be used to reduce its usage. When looking at various statically-linked executables, one could quickly realize that they were composed of identical piece of codes: those that are reused. As such, it would make sense if these reused codes were only present on disk once and loaded, on-demand, by processes that need them. To this end, a new linking technique was developed. Dynamic linking (sometimes called deferred linking) is the technique used to link programs and libraries together at run-time. Libraries that can be shared/reused in such a way are called shared libraries3 (or dynamic libraries, or dynamically-shared objects, DSO) and programs that use them are called dynamically-linked executables. In practice, a dynamically-linked executable contains a list of the shared libraries it needs to run as well as the list of symbols (functions, variables, etc.) it needs from each of them. When these executables are executed, a specialized linker, called, a dynamic linker (or run-time loader, or interpreter) is launched to load the executable and its required libraries in memory before yielding control to it.

Dynamic linking also enables programs to load additional, non-required, shared libraries (to be precise: functions in shared libraries) at run-time, if desired. A good example of programs that make use of this technique are Web browsers; that support loading addons/plugins after it started.
Dynamic loading is a technique to add code coming from shared libraries into a process's address space, at run-time.
Memory protections
As I presented earlier, modern operating systems take great care in ensuring that processes only have access to memory they are meant to access. However, virtual memory, by itself, does not prevent a process from corrupting itself. What if a program is buggy and rewrites its code and goes out of control, destroying precious data in the process? In practice, virtual memory pages allows protecting against such bugs (and attacks) through memory usage flags.
Let's consider the simplest memory usage mode: no protections. Memory is writable (to store and modify data), readable (to retrieve stored data) and executable (to execute the code stored in memory). From a reliability and security perspective, it's dangerous for the memory containing code to be writable and it's dangerous for the memory containing writable data to be executable. Without protections, a buggy software can corrupt its own code at runtime, be exploited to rewrite its code to something malicious or hijacked to execute code that was placed in memory by an attacker. Clearly, all undesirable behaviors/events.
To improve the state of things, the "W^X"45, write xor execute, policy was introduced and rapidly adopted by other operating systems. Introduced in OpenBSD 3.3, W^X simply dictates that any memory page that is writable cannot be executable at the same time. That policy is only possible because it is supported by the processor. In practice, every page has a set of protection flags (read, write, executable) that dictates how it can be used. If a process tries to access a page in a way that's not allowed, a memory access violation occurs.
Data Execution Prevention is the term Microsoft adopted for its W^X policy implementation in Windows.
Memory segments have access modes that dictate how they can be used. An access mode is a combination of "readable", "writable" and "executable" rights. Security policies such as the W^X policy are designed to prevent bugs from causing stability and security issues.
The structure of programs and processes
To support6 the mechanisms described above, programs are separated in different sections: code, read-only data and writable data. For the reasons explained above, in common configurations:
- code sections are readable and executable;
- read-only data sections are readable;
- writable data sections are readable and writable.
The stack (which is not part of a program, but of a process) is a readable and writable data section; unless marked executable in its program file.
When a program is loaded in memory, its stack is setup by the kernel,
each section gets loaded into different pages and the corresponding
protection flags are applied to each of them. If needed, a process can,
at run-time, request more memory from the kernel (denoted to be
dynamically-allocated memory) that will be backed by readable-writable
memory pages. In the picture below, we can look at the different
sections of a /bin/ls binary and their corresponding memory protection
flags (R, W and E).
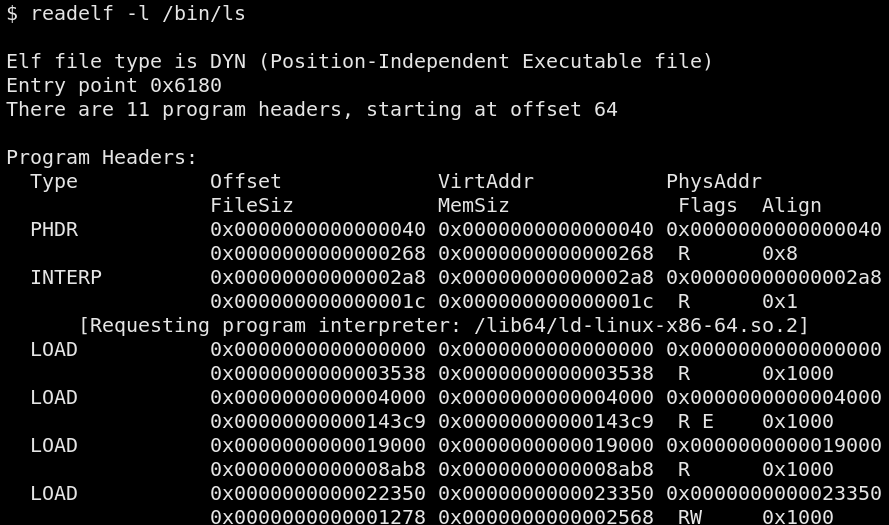
Parts of an executable file are copied to memory pages and applied their corresponding protection flags. The stack, setup by the kernel, is readable and writable, but not executable, unless explicitly requested/marked otherwise by the program.
What we've seen so far
Process injection is mostly considered an advanced technique due to the amount of knowledge required to understand, design and perform them correctly. While I didn't touch details that are relevant for particularly sophisticated injection techniques, I hope this brief tour into operating systems will help to approach them. If you would like to read more about injection, feel free to move on to part 2 of this series.
Articles in this series
- Part 1 - Introduction
- Part 2 - Injecting into Processes
- Part 3 - Prevention and Detection
- Part 4 - Advanced Injection Topics
- Part 5 - Technical Reference
Recommended reading
- Wikipedia - Memory paging
- Wikipedia - W^X
- Tanenbaum, Andrew S. - Modern Operating Systems, 3rd Edition
- Levine, John. R - Linkers and Loaders
References
- Intel 64 and IA-32 Architectures Software Developer Manuals
- time(7)
- Microsoft - Data Execution Prevention
- elf(5)
I'm trying to condense one of the most complex topics of software engineering in a graspable format. Some corners are consciously cut short for the sake of the topic. Interested readers are strongly encouraged to grab a copy of the recommended books. ↩︎
This section is written with the Intel architecture in mind and, while many concepts equally apply to other architectures, there are a wide variety of machines and operating systems available. The text does not apply to all systems. ↩︎
External libraries used to build static executables are called "static libraries". ↩︎
I'm not entirely clear on the origin of the mechanism. Feel free to update me. ↩︎
In reality, sections were introduced much earlier. The order of presentation makes it simpler to present sections at the end. ↩︎